카프카 리벨런싱에 대하여 (Kafka Rebalancing)
이 글은 Apache Kafka Rebalance Protocol, or the magic behind your streams applications 을 일부 번역한 것입니다.
카프카 리벨런싱은 Group Membership Protocol 과 Client Embedded Protocol 이라는 두 가지 프로토콜을 기반으로 이루어집니다.
JoinGroup
컨슈머가 새로 시작할 때, 자신의 그룹을 관리하는 카프카 브로커의 coordinator를 찾기 위해 FindCoordinator 요청을 보냅니다.
그리고 나서, JoinGroup 요청을 통해 리벨런싱 프로토콜을 시작합니다.
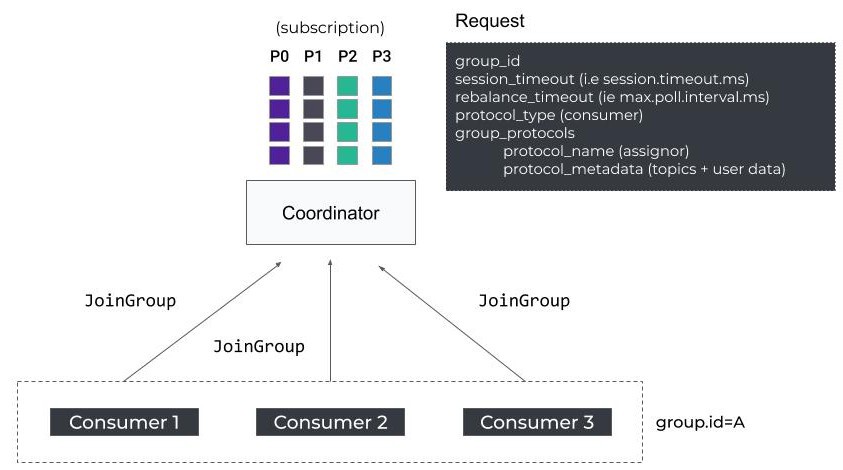
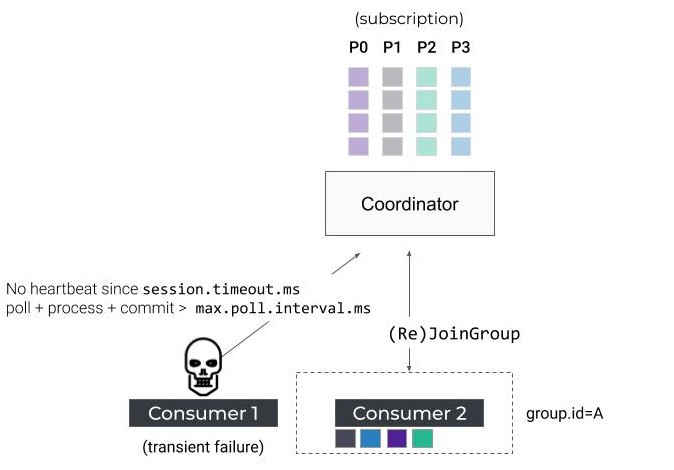
JoinGroup 요청은 session.timeout.ms와 max.poll.interval.ms 등의 클라이언트 설정들을 포함합니다.
coordinator는 이 설정들을 그룹에서 컨슈머들로부터 응답이 없을 경우 제외시키기 위한 기준으로 사용합니다.
추가로, 이 요청은 두 가지 중요한 필드들을 포함합니다: 사용 가능한 client protocol의 목록, 그리고 프로토콜을 실행시킬 때 필요한 메타데이터들을 보냅니다.
client-protocol 은 partition.assignment.strategy 와 같은 컨슈머의 partition assignor 의 목록입니다.
메타 데이터들은 컨슈머가 구독하고 있는 topic 들입니다.
JoinGroup 은 일종의 베리어 역할을 합니다.
즉, coordinator는 모든 컨슈머로부터 해당 요청을 받기 전(group.initial.rebalance.delay.ms)까지, 혹은 rebalance timeout 이 발생하기 전까지 응답하지 않습니다.
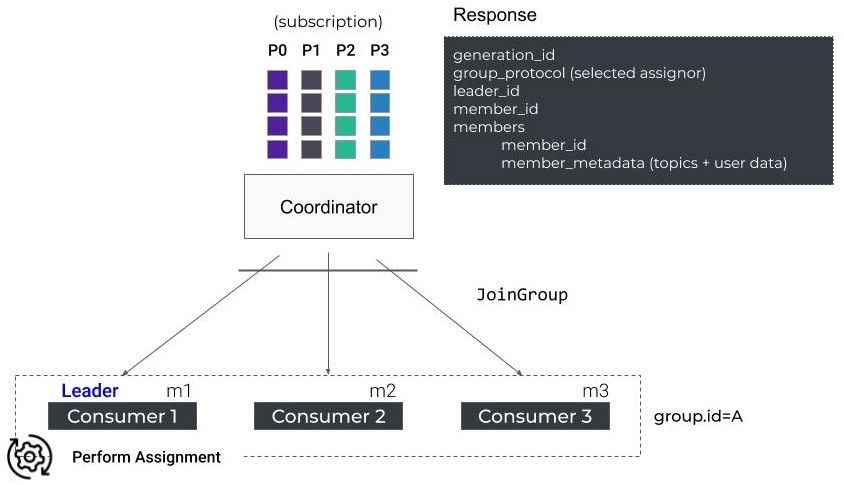
그룹 안의 첫 번째 컨슈머는 group leader로서 활동하며, 정상 작동중인 구성원들의 목록, 그리고 선택된 assignment strategy를 응답받습니다. group leader는 파티션 배정의 책임을 지게 됩니다.
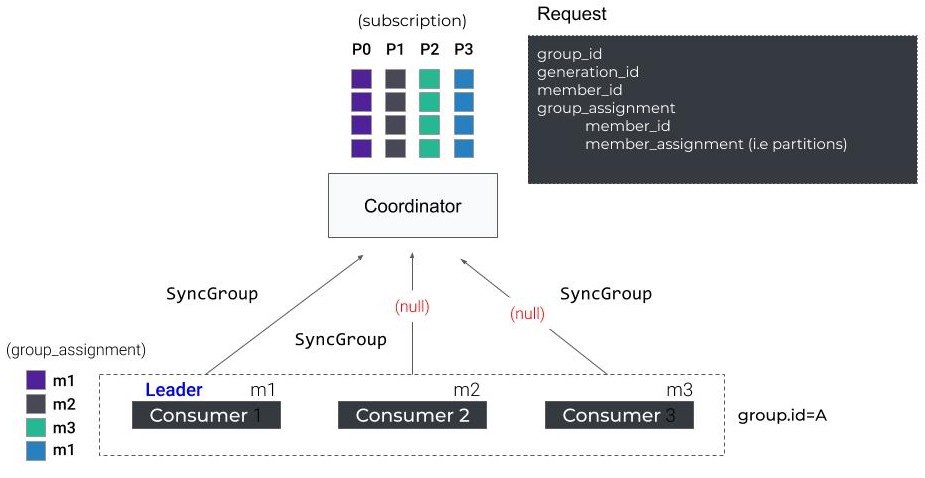
SyncGroup
다음으로 모든 구성원들은 coordinator에게 SyncGroup 요청을 보냅니다.
그룹 리더는 계산한 파티션 배치를 함께 보내며, 다른 컨슈머들은 그냥 빈 요청을 보냅니다.
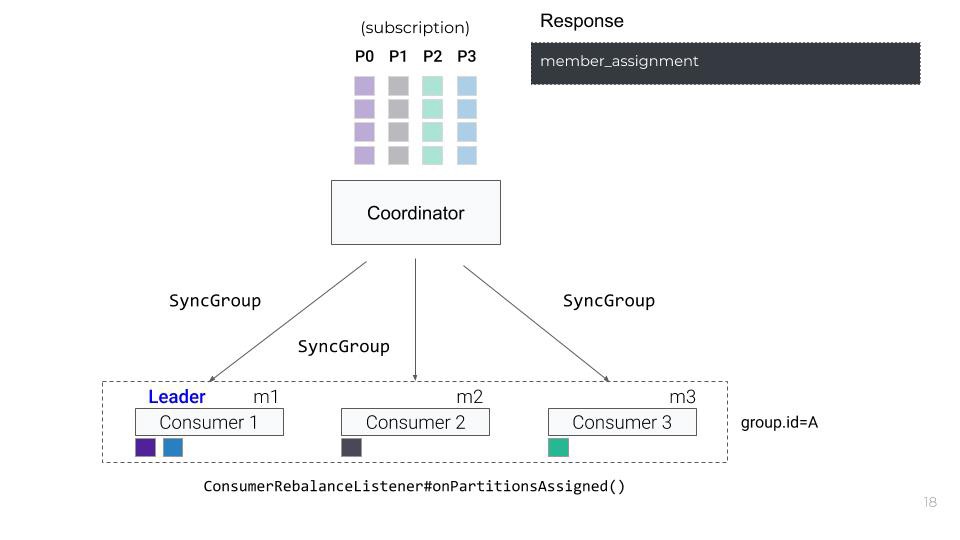
coordinator는 모든 SyncGroup 요청에 응답을 보내고, 각각의 컨슈머들은 그들에게 배정된 파티션들을 응답받습니다.
그리고 onPartitionsAssignmedMethod 가 실행되며, 메시지들을 fetch 해오기 시작합니다.
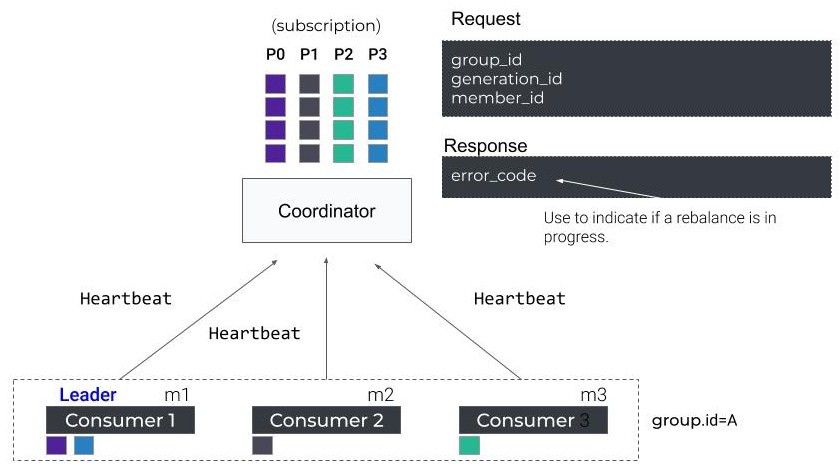
Heartbeat
마지막으로 가장 중요한 것은, 각각의 컨슈머들은 session을 유지하기 위해 주기적으로 Heartbeat 요청을 브로커 coordinator에게 보내는다는 것입니다.(heartbeat.interval.ms)
만약 리벨런싱이 진행중인 경우, coordinator 는 Heartbeat 응답으로 컨슈머에게 그룹 rejoin이 필요하다고 알려줍니다.
몇 가지 주의점
리벨런싱 프로토콜의 첫 번째 한계점은 전체를 멈추지 않고는 리벨런싱을 완료할 수 없다는 것입니다. (stop-the-world effect)
예룰 들어, 하나의 인스턴스를 멈춰봅시다.
첫 번째 리벨런싱은 컨슈머가 coordinator에게 멈추기 전 LeaveGroup 요청을 보내면서 시작됩니다.
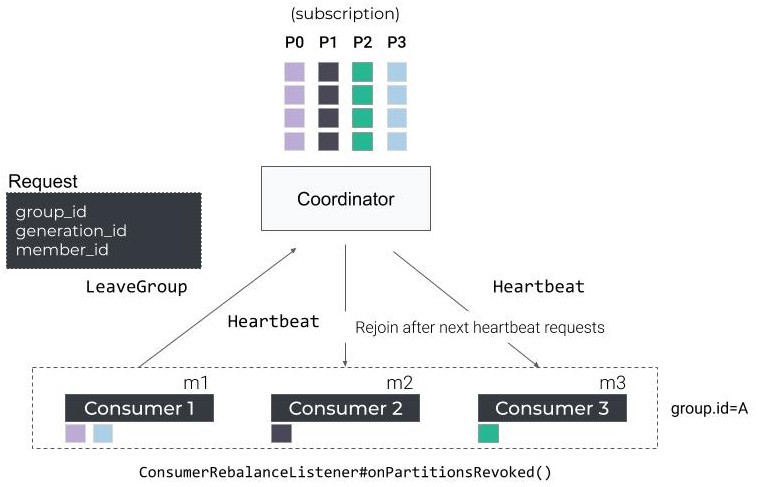
남아 있는 컨슈머들은 다음 번 Heartbeat 때에야 리벨런싱이 필요하다는 사실을 알게 되고, 파티션 재배치를 위해 새로운 JoinGroup/SyncGroup 을 시작하게 될겁니다.
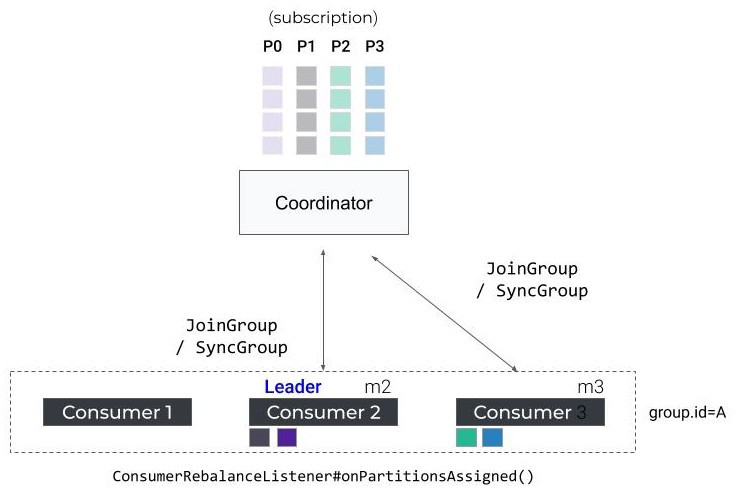
파티션 재조정이 끝나기 전까지는, 컨슈머들은 아무런 데이터도 처리할 수 없습니다. 기본적으로 rebalance timeout은 5분으로 설정되어 있으며 상황에 따라서는 매우 큰 consumer-lag을 유발할 수 있습니다.
문제는 컨슈머가 다시 시작되면 어떤 일이 발생할까요? 컨슈머는 다시 그룹에 참여하기 위해 새로운 리벨런싱을 유발할 것이고, 또다시 전체 컨슈머가 멈추는 일이 발생할 것입니다.
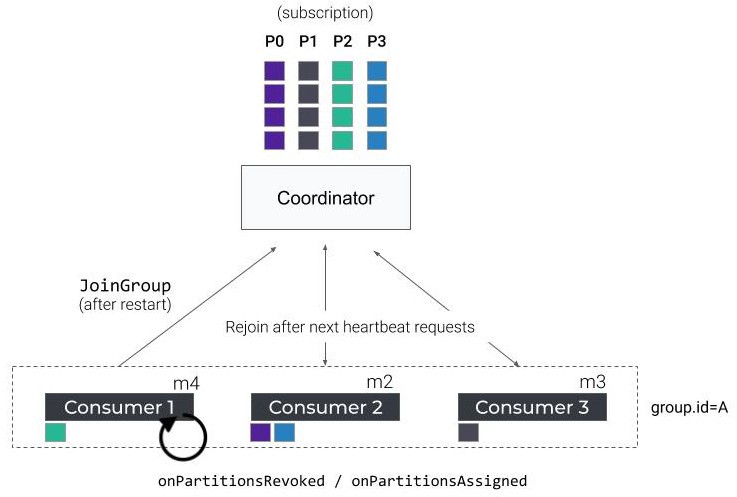
이와 같은 재시작은 rolling update 시에도 발생할 수 있습니다. 이런 시나리오는 컨슈머들에게는 매우 안 좋습니다. 실제로 세 개의 컨슈머들이 재시작 되면 총 6번의 파티션 재조정이 발생합니다.
최종적으로 카프카 컨슈머에서 가장 흔히 발생하는 문제는 네트워크 장애, 긴 GC 시간 등으로 heartbeat 요청이 실패한 경우와
데이터를 처리하는데 오래 걸려 poll 요청을 못하는 경우입니다.
첫 번째 경우, coordinator 는 session.timeout.ms 만큼의 시간동안 heartbeat 요청을 못받으면 컨슈머가 죽었다고 생각합니다.
두 번째의 경우, 데이터를 처리하는데 걸리는 시간은 max.poll.interval.ms 시간보다 적어야 합니다.
리벨런싱을 효율적으로 하기 위한 몇 가지 방안들이 카프카 2.3 이후로 나왔습니다. 대표적으로는 static membership, incremental cooperative rebalancing 이 있습니다. 이와 같은 방법에 대해서는 Apache Kafka Rebalance Protocol, or the magic behind your streams applications의 글 뒷부분을 참조해주시기 바랍니다.
댓글남기기