Java 동시성에 대하여
멀티 쓰레딩에 대해 고민하는 시기가 오게 됩니다. 하지만 처음 구글링을 하다보면 생각보다 매우 다양한 정보에 휩쓸리게 됩니다. Thread, ExecutorService, Future, Parallel Stream 등등.. 이 글에서는 이론적인 내용부터 어플리케이션 레벨, 그리고 하드웨어 레벨까지 동시성에 대한 개념들을 포괄적으로 설명할 예정입니다. 어떻게 보면 제가 공부한 레퍼런스들의 총 집합이라고 볼 수 있겠습니다.
- “쓰레드”란 무엇이고, 어떻게 동시성 작업을 진행하는지 간단하게 살펴볼 것입니다.
- Java 에서 제공하는 동시성 프로그래밍 방법들을 알아볼 것입니다.
- 동시성을 언제 사용하는지, 동시성 설계 시 주의점, 발생할 수 있는 문제점들을 알아볼 것입니다.
프로세스와 쓰레드
어떤 프로그램을 실행시킬 때, 운영체제는 시스템에서 그 한 개의 프로그램만 실행되는 것 같은 착각에 빠지게 해줍니다. 그 프로그램의 내용들이 아무런 방해 없이 순차적으로 이뤄지고 있는 것으로 보이지요. 이러한 환상은 “프로세스”라는 개념으로 만들어집니다.
프로세스란 실행 중인 프로그램에 대한 운영체제의 추상화입니다. 간단하게는 실행중인 프로그램이라고 생각하셔도 됩니다.
보통 우리는 하나의 컴퓨터에서 여러 프로세스를 동시에 실행시킵니다. 하지만 실제로 단일 코어 환경에서, 운영체제는 어느 한 순간에 하나의 프로세스 코드만을 실행할 수 있습니다. 그렇다면 어떻게 동시에 프로세스들이 실행되는 것처럼 보이게 하는 걸까요?
운영체제는 문맥 전환(context switching) 이라는 방법을 사용해 이를 가능하게 합니다. 여러 개의 프로세스를 빠르게 번갈아가며 교차 실행하는 방식이죠.
운영체제는 프로세스가 실행되는데 필요한 모든 상태정보의 변화를 추적합니다. 문맥, 컨텍스트(context) 라고 부르는 상태정보는 PC, 레지스터 파일, 메인 메모리의 현재 값을 포함하고 있습니다. 운영체제는 현재 프로세스에서 다른 새로운 프로세스로 제어를 옮기려고 할 때 현재 프로세스의 컨텍스트를 저장하고, 새로운 프로세스의 컨텍스트를 복원시키는 문맥전환을 사용하여 제어권을 새 프로세스에게 넘겨줍니다.
쓰레드는 프로세스에 존재하는 실행 유닛, 혹은 제어 흐름입니다. 프로세스와 마찬가지로 추상적인 단위이며, 실제로 CPU 자원을 할당받아 실행되는 단위입니다. 프로세스는 하나의 쓰레드만 가질 수도 있고, 여러 개의 쓰레드를 가질 수도 있습니다. 여러 개의 쓰레드를 갖고 있을 경우 위에서 설명한 문맥전환과 비슷한 방법으로 CPU에 스케줄링 됩니다.
쓰레드라는 개념은 하드웨어 레벨과 어플리케이션 레벨로 분리해서 생각하는 것이 이해가 쉽습니다. 프로그램에서 사용하는 쓰레드는 하나의 제어 흐름 단위라고 생각하시면 됩니다. 반면, 하드웨어에서 사용하는 쓰레드는 CPU에 할당되어 실제로 일을 처리하는 단위입니다.
쓰레드도 앞서 설명한 문맥전환과 같은 방법을 이용하여 교차적으로 CPU에 할당되기 때문에, 프로그램에서는 하드웨어의 쓰레드보다 많은 수의 쓰레드를 이용할 수 있습니다.
출처: 컴퓨터 시스템 Chapter1
멀티 쓰레딩은 언제 필요한가? - 처리량 높이기
주로 멀티쓰레딩은 처리량을 높이기 위해 사용할 수 있습니다. 하지만 멀티 쓰레딩은 항상 처리량을 높여주지는 않습니다. 일반적으로 1. 대기 시간이 긴 작업이 있거나, 여러 프로세서가 동시에 처리할 2. 독립적인 계산이 충분히 많은 경우에 성능이 높아집니다. 왜 그런지 다음 예시를 통해 살펴보겠습니다.
대기 시간이 긴 작업은 주로 네트워크 응답을 기다리거나 I/O를 기다리는 시간입니다. 다음과 같이 페이지를 읽어오고 처리하는 작업이 있다고 가정해봅시다:
- 페이지를 읽어오는 평균 I/O 시간: 1초
- 페이지를 분석하는 평균 처리 시간: 0.5초
- 처리는 CPU 100% 사용, I/O는 CPU 0% 사용
1개의 쓰레드로 3개의 페이지를 처리하는데 걸리는 시간은 1.5초 X N 입니다.
반면, 3개의 쓰레드로 처리할 경우, I/O 를 기다리는 1초 동안 두 개의 페이지를 처리 할 수 있습니다. 그러므로 처리율은 1개의 쓰레드를 이용할 때의 3배가 될 것입니다.
출처: 클린코드, 부록 A 동시성
이제 Java 에서 어떻게 멀티 쓰레딩을 활용할 수 있는지 확인해봅시다.
Thread
구글에 “Java 멀티 쓰레드 구현”이라고 검색하면 처음에 가장 많이 나오는 방법입니다.
보통 Runnable 한 태스크를 만든 뒤, 새로운 쓰레드를 만들고 해당 쓰레드를 start() 합니다.
Thread 를 사용하여 병렬로 f(), g() 함수를 실행하는 간단한 예시입니다:
Thread t1 = new Thread(() -> { result.left = f(x); });
Thread t2 = new Thread(() -> { result.right = g(x); });
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(result.left + result.right);
출처: 모던 자바 인 액션
ExecutorService
ExecutorService 는 비동기 작업들을 쓰레드를 직접 관리하지 않고 실행 할 수 있는 인터페이스를 제공합니다.
Task 를 실행할 수 있는 submit 메서드가 존재합니다.
쓰레드 풀과 ThreadPoolExecutor
쓰레드 풀은 말 그대로 미리 생성해둔 쓰레드들이 모여 있는 곳입니다. 태스크가 제출되면 차례대로 작업 큐에 들어가서 쓰레드를 할당받을 때까지 기다립니다. 쓰레드는 작업 큐에서 태스크를 하나씩 가져가 처리합니다.
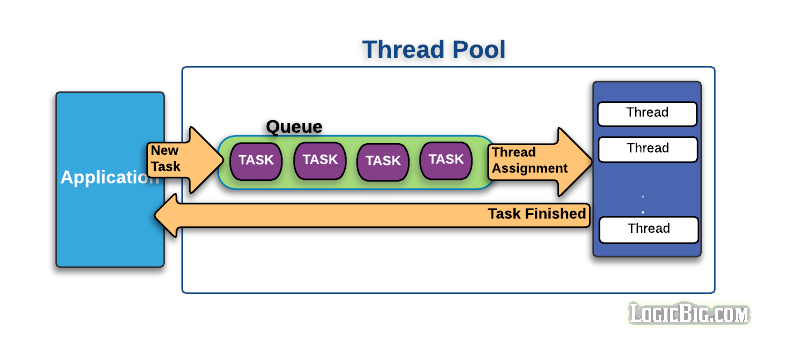
출처: https://limkydev.tistory.com/55
ThreadPoolExecutor 는 ExecutorService의 구현체이며 앞서 설명한 쓰레드 풀을 이용하여 비동기로 작업들을 실행합니다.
주로 Executors 의 펙토리 메서드들을 사용하여 생성합니다.
ExecutorService executorService = Executors.newFixedThreadPool(2);
Future<Integer> y = executorService.submit(() -> f(x));
Future<Integer> z = executorService.submit(() -> g(x));
System.out.println(y.get() + z.get());
쓰레드풀 주의사항
-
잠을 자거나 I/O, 네트워크 연결을 기다리는 테스크가 있다면 주의.
n개의 쓰레드를 가진 쓰레드 풀은 오직 n개의 쓰레드를 동시에 실행시킬 수 있습니다. 예를 들어 5개의 쓰레드 풀에서 3개의 쓰레드에서 기다리는 작업이 있다면 그동안은 두 개의 쓰레드에서만 작업 처리가 가능합니다. 따라서 적당한 쓰레드 수를 설정해줍시다.
-
모든 쓰레드 풀을 종료하는 습관을 갖자.
다음 태스크를 기다리면서 쓰레드 풀이 종료가 안될 수 있습니다. 이런 상황을 해결하기 위해서
Thread.setDaemon메서드를 이용해 데몬 쓰레드로 설정할 수 있습니다. 데몬 쓰레드는 어플리케이션이 종료될 때 강제 종료됩니다. (main() 메서드는 모든 비데몬 쓰레드가 종료되기까지 기다립니다.)
출처: 모던 자바 인 액션
Future
위 예시에서 ExecutorService 의 submit() 메서드를 보면 Future 타입을 반환합니다.
이는 무엇일까요?
문서를 살펴보면 비동기 작업의 결과를 나타낸다고 합니다.
isDone(), isCancelled() 등의 메서드로 태스크의 상태를 확인할 수 있고,
get() 메서드를 통해 태스크의 결과를 가져올 수 있습니다.
다만, get() 함수를 호출할 때 결과가 다 계산되지 않았을 경우 해당 위치에서 기다립니다 (block).
Future를 실제로 사용하는 예시들을 소개해드릴 예정입니다.
그 전에 앞서 Future 의 구현체인 CompletableFuture 클래스의
complete, completeExceptionally, supplyAsync 메서드들도 한 번 둘러보시길 바랍니다.
비동기 실제 사용 예시
카프카 클라이언트 코드(2.0.0)를 보면서 실제로 사용된 예시를 하나 살펴보겠습니다.
KafkaAdminClient 에는 카프카 브로커와 네트워크를 통해 통신하는 부분이 있습니다.
예를 들어 listConsumerGroupOffsets 함수를 보면 다음과 같은 방식으로 응답을 반환합니다.
// Future 객체 생성
TopicPartition, OffsetAndMetadata>> groupOffsetListingFuture = new KafkaFutureImpl<>();
...
if (response.hasError()) {
// 예외 처리
groupOffsetListingFuture.completeExceptionally(response.error().exception());
} else{
...
// 응답 처리
groupOffsetListingFuture.complete(groupOffsetsListing);
}
// Future 객체 반환
return new ListConsumerGroupOffsetsResult(groupOffsetListingFuture);
생략을 많이 해서 그렇지만 groupOffsetsListing 값 역시 콜백 형식으로 비동기적으로 할당됩니다.
책에 있는 다른 예시를 하나 더 살펴보겠습니다.
다음 함수는 상품을 인자로 받고 가격을 Future 를 반환합니다.
public Future<Double> getPriceAsync(String product) {
return CompletableFuture.supplyAsync(() -> calculatePrice(product));
}
출처: 모던 자바 인 액션
ForkJoinPool
ForkJoinPool 은 앞서 살펴보았던 쓰레드 풀 방식에서 알고리즘을 추가하여 병렬적으로 태스크를 실행할 수 있는 ExecutorService 의 구현체입니다.
포크/조인 프레임워크라고 부르는데요, 이를 사용하기 위해서는 RecursiveTask,
RecursiveAction 등을 상속받아 구현하셔야 합니다.
포크 조인 프레임워크는 하나의 큰 작업을 여러개의 작은 작업들로 나눕니다. 적당히 작은 크기까지 나눠지게 되면 해당 작업을 처리하고 결과를 반환합니다. 각각의 작업 결과들을 다시 합쳐서 최종 결과를 반환하게 됩니다. 어떻게 보면 divide and conquer 알고리즘과 비슷합니다.
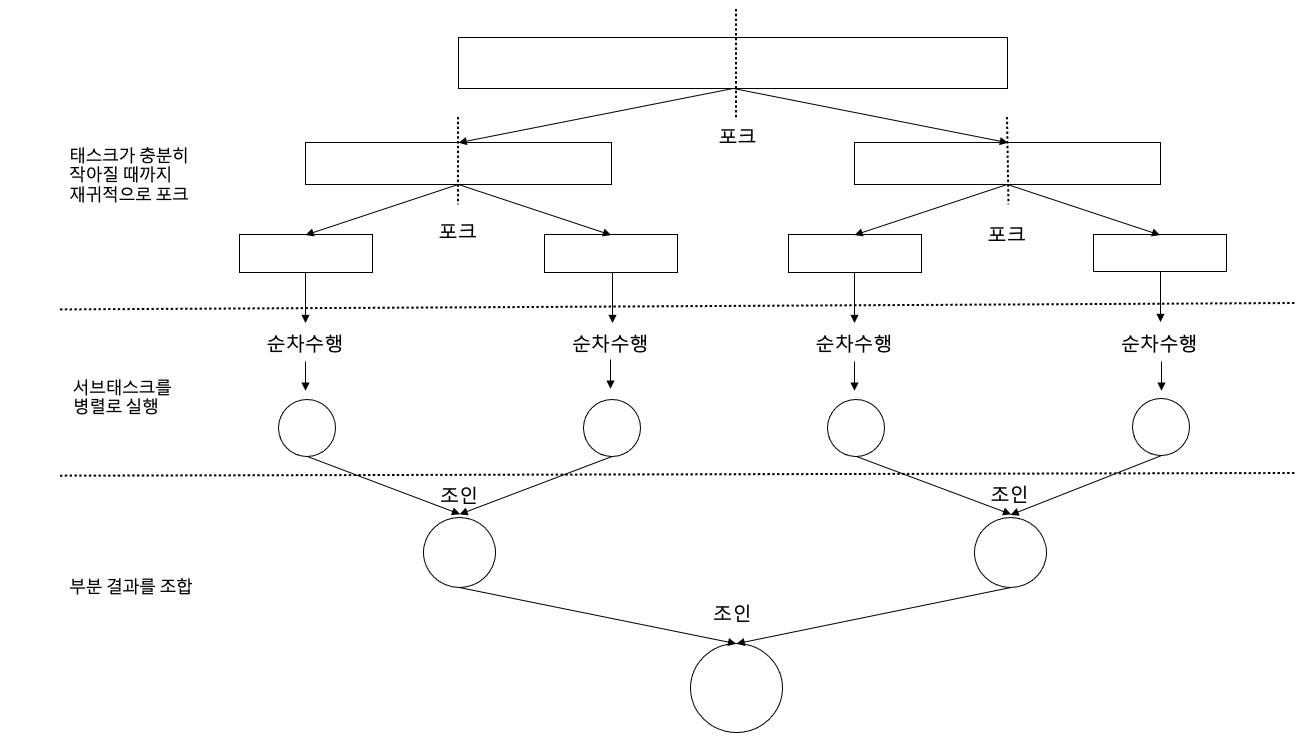
그렇기 때문에 저희가 주로 구현해야할 부분의 의사코드는 다음과 같습니다.
// compute 메서드
if (태스크가 충분히 작거나 더 이상 분할할 수 없으면) {
순차적으로 태스크 계산
} else {
태스크를 두 서브태스크로 분할
태스크가 다시 서브태스크로 분할되도록 이 메서드를 재귀적으로 호출
모든 서브태스크의 연산이 완료될 때까지 기다림
각 서브태스크의 결과를 합침
}
출처: 모던 자바 인 액션
그렇다면 쓰레드 풀 방식보다 이 방식이 좋은 점은 무엇일까요?
포크/조인 프레임워크는 각각의 쓰레드가 더 이상 배정된 태스크가 없을 때, 다른 쓰레드로부터 work-stealing을 합니다.
포크/조인 프레임워크를 사용하지 않고 4개의 쓰레드에 작업 시간이 다른 태스크 4개를 제출했을 때 모습입니다:
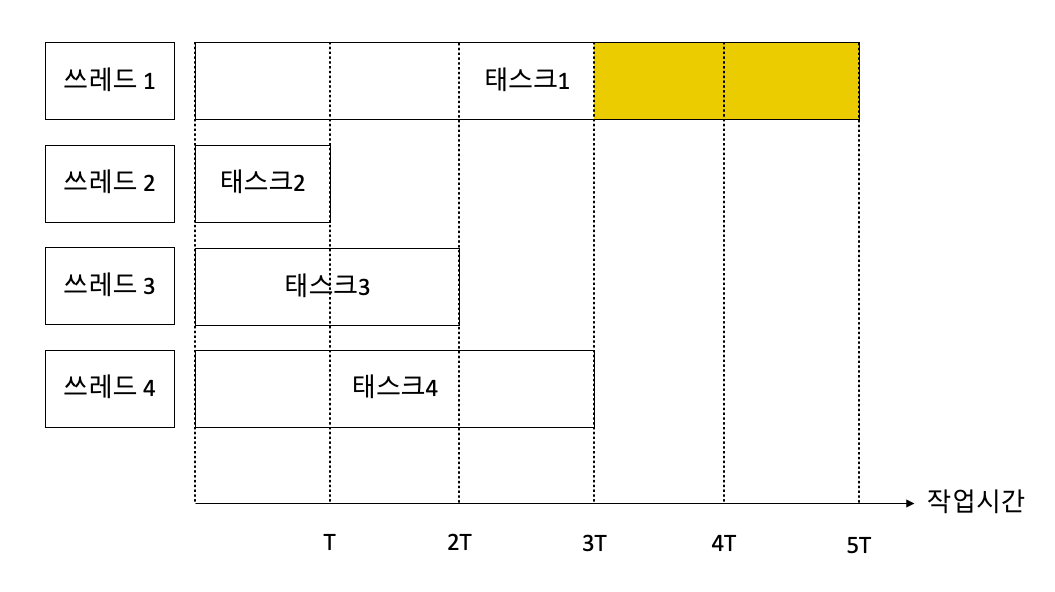
포크/조인 프레임워크를 사용하여 태스크를 서브태스크로 충분히 작게 나눈 후 work-stealing 과정이 일어날 때의 모습입니다:

하나의 태스크를 여러 개의 서브 태스크로 나누는데도 비용이 들어갑니다. 따라서 서브태스크로 나누는데 드는 비용과 서브태스크를 처리하는데 드는 비용을 잘 고려하여 충분히 작은 서브태스크 크기를 결정하시기 바랍니다.
포크/조인 프레임워크를 살펴본 이유는 다음에 나올 Parallel Stream 에서 포크/조인 프레임워크를 사용하기 때문입니다.
Parallel Stream
Java Stream 을 사용하다보면 parallel() 함수를 이용해 매우 손쉽게 병렬로 처리할 수 있습니다.
병렬로 처리하면 막연히 빨라질 것이라는 기대를 하게 합니다.
그러나 이제는 parallel stream 이 어떤 방식으로 동작하는지 알고 있으므로 어느 부분에 주의해야 할지 생각해볼 수 있습니다.
분할
Parallel Stream 을 이용하게 되면 내부에서 포크/조인 프레임워크에 따라 Stream 들이 작은 크기의 Stream 들로 분할 될 것입니다.
분할 알고리즘은 Spliterator 인터페이스에서 담당하며,
기본 자료구조들은 미리 정의된 Spliterator 를 반환하는 메서드들을 포함하고 있습니다.
LinkedList 같은 경우 iterate 하면서 분할하지만, ArrayList 의 경우 index를 통해 요소들을 탐색하지 않아도 분할할 수 있으므로 분할 속도가 더 빠릅니다.
비슷한 이유로 분할 시 iterate 를 해야하는 자료구조는 분할 속도가 느립니다.
기본 Spliterator 를 사용할 경우에는 매우 작은 크기로 분할되기 때문에 요소 하나하나의 처리 시간이 오래 걸릴 수록 병렬 스트림을 효과적으로 사용할 여지가 높습니다. 요소 하나하나의 처리 시간이 짧을 경우 분할 과정에서 생기는 비용이 더 클 수 있기 때문이죠.
소량의 데이터를 병렬로 작업하는 경우에는 분할 과정에서 생기는 추가 비용을 상쇄할 수 있을 만큼의 이득을 얻지 못할 가능성이 높습니다.
Custom Spliterator 를 이용하여 분할 과정을 제어할 수도 있습니다.
병합
최종 연산의 병합 과정에 드는 비용도 고려해봐야합니다.
Collectors 의 combiner 메서드들의 비용도 한 번 살펴보시기 바랍니다.
순서
분할과 병합의 과정이 있으므로 요소 순서가 중요하지 않은 태스크를 병렬 스트림으로 실행할 때 더욱 효과적입니다.
쓰레드 풀
병렬 스트림은 내부적으로 ForkJoinPool 을 사용합니다.
기본적으로는 프로세서 수에 따라 쓰레드 풀 수가 결정됩니다.
이를 변경할 수도 있고, 원한다면 custom ForkJoinPool 을 생성하여 parallel stream 을 실행할 수도 있습니다.
가장 중요한 것
순차 스트림을 사용할지, 병렬 스트림을 사용할지 고민된다면 가장 중요한 것은 측정입니다.
출처: 모던 자바 인 액션
공유 객체
멀티 쓰레딩을 이용하면, 동일한 객체에 여러 쓰레드가 동시에 접근하여 알 수 없는 일들이 벌어지곤 합니다. 아래와 같은 클래스를 통해 간단한 예를 보여주고자 합니다.
public class IdGenerator{
int lastId;
public int incrementValue() {
return ++lastId;
}
}
lastId 의 초기값이 93이라고 가정하고 두 개의 쓰레드가 동일한 객체에 접근하여 incrementValue() 메서드를 호출할 때,
다음과 같이 세 가지 경우가 모두 가능합니다.
특히 마지막 경우도 가능하다는 점을 눈여겨 보시기 바랍니다.
- 쓰레드 1이 94를 얻고, 쓰레드 2가 95를 얻고, lastId 가 95가 된다.
- 쓰레드 1이 95를 얻고, 쓰레드 2가 94를 얻고, lastId 가 95가 된다.
- 쓰레드 1이 94를 얻고, 쓰레드 2가 94를 얻고, lastId 가 94가 된다.
그 이유는 ++ 가 원자적 연산이 아니기 때문입니다.
보통 이런 경우, synchronized 키워드를 통해 해결할 수 있습니다.
synchronized로 선언된 부분은 한 쓰레드가 접근할 때 lock 을 걸어 다른 쓰레드에서 접근하지 못하도록 합니다.
하지만, 그런 이유로 성능상 퍼포먼스가 떨어질 수 있습니다.
자바는 위와 같은 상황에서 사용할 수 있는 AtomicInteger, AtomicBoolean 등의 클래스들을 지원합니다.
해당 클래스들은 synchronized 키워드를 사용할 때보다 거의 더 빠릅니다.
(엇비슷한 경우는 있어도 느린 경우는 없습니다.)
위 클래스들은 현대 프로세서에서 제공하는 CAS 라는 연산을 통해 미리 lock 을 걸기 보다는, 문제를 감지하는 쪽으로 동작하기 때문입니다.
출처: 클린 코드, 부록 A 동시성2
댓글남기기